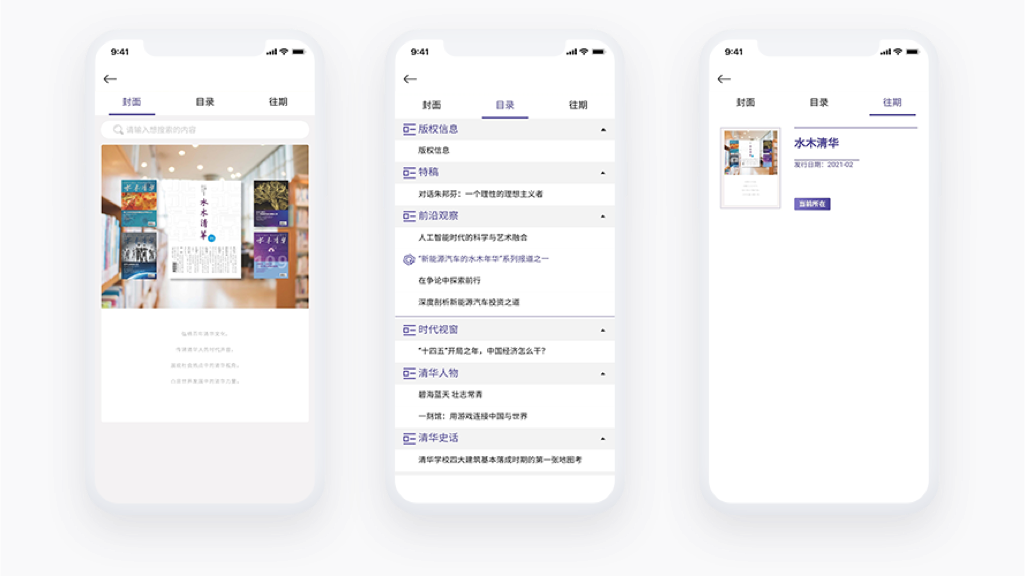
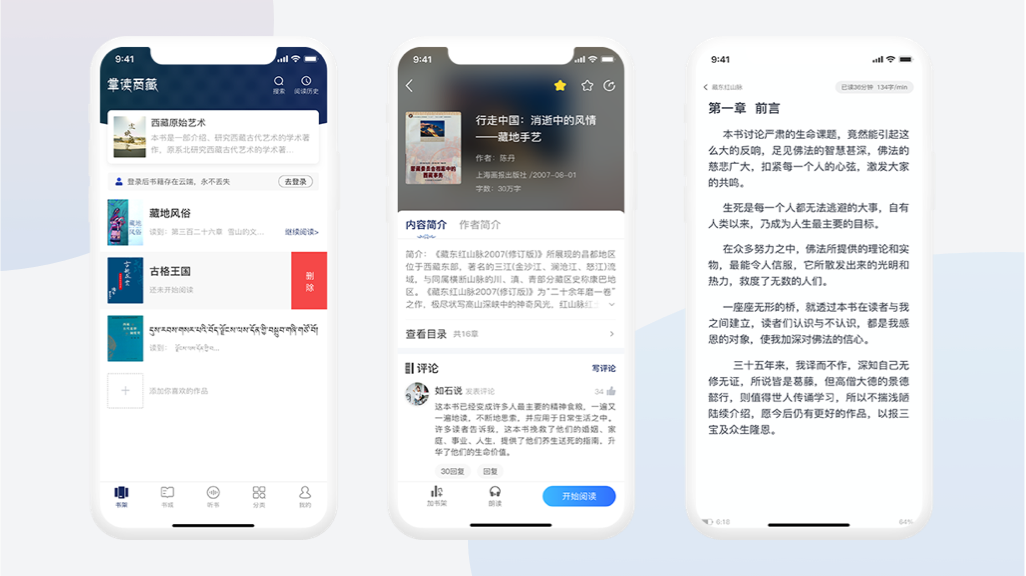
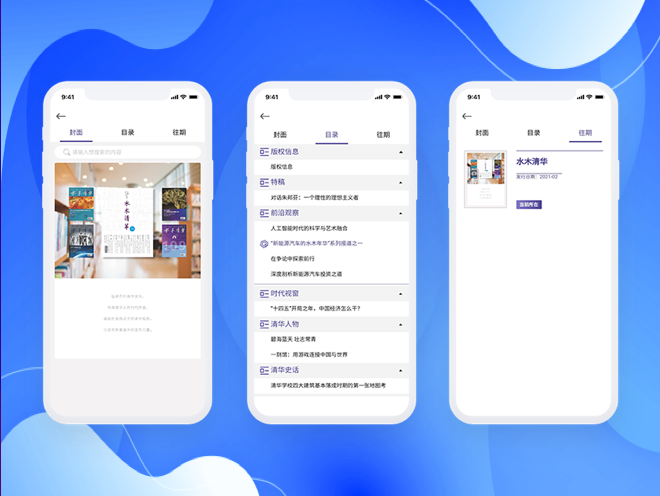
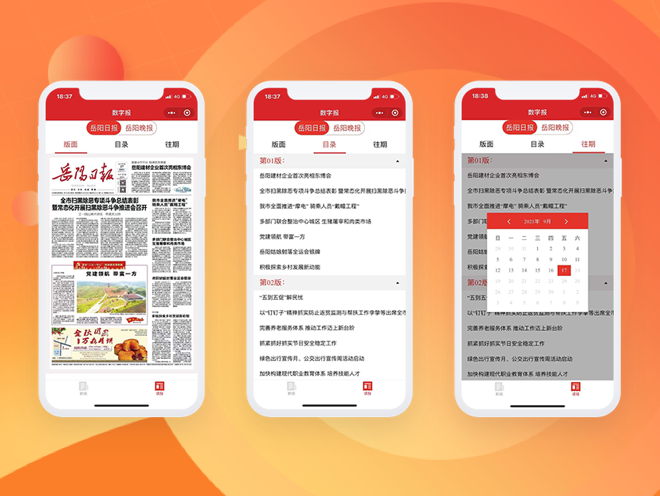
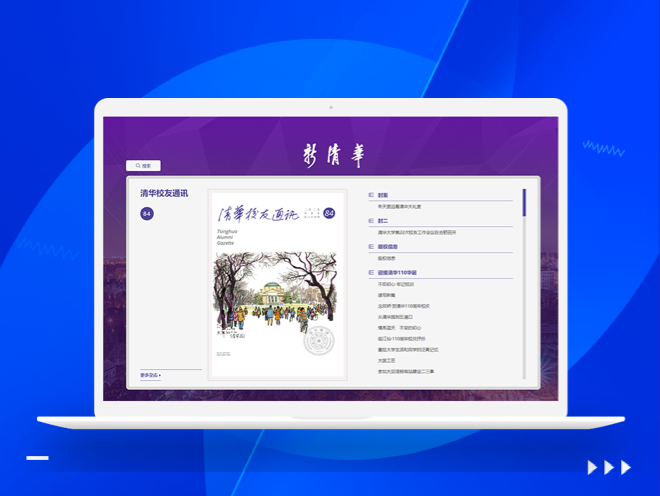
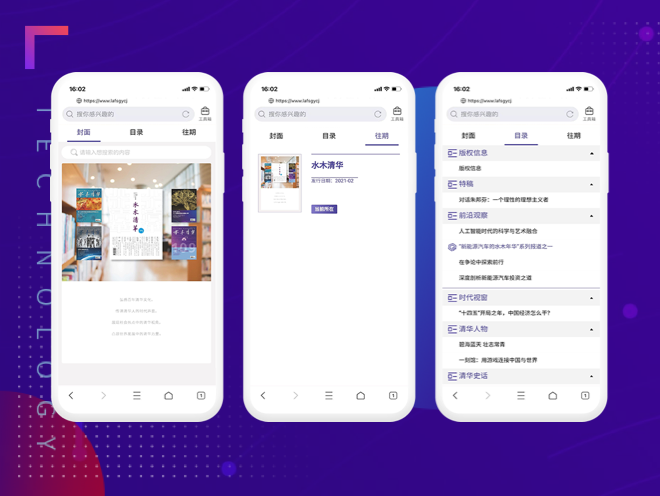
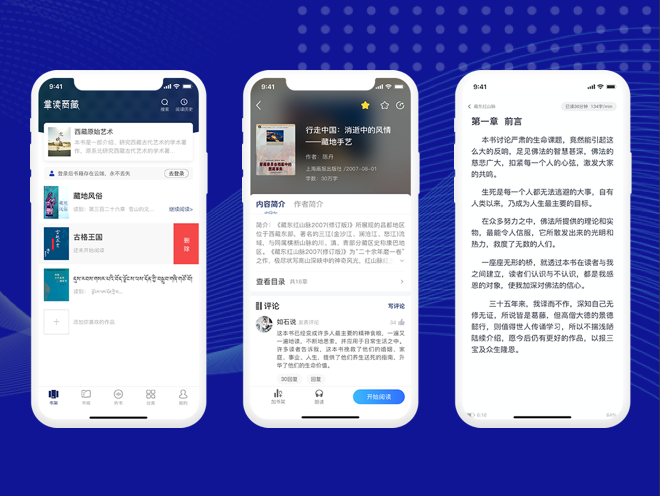
数字报电子期刊解决方案
报纸扫描标引加工平台是一套科技含量极高的软件系统,由扫描生产流程子系统和报纸发布子系统组成,该系统的基本原理是通过扫描设备,将纸介质的报纸扫描成数字图像,再经过图像处理、版面分析、文字识别、文字校对、版面重构、标引加工、文档精细加工等一系列步骤,最终形成可以方便应用的精美的电子文档,在此基础上,对这些电子文档进行数字化发布,形成可以供全网使用的数字资源。
方案咨询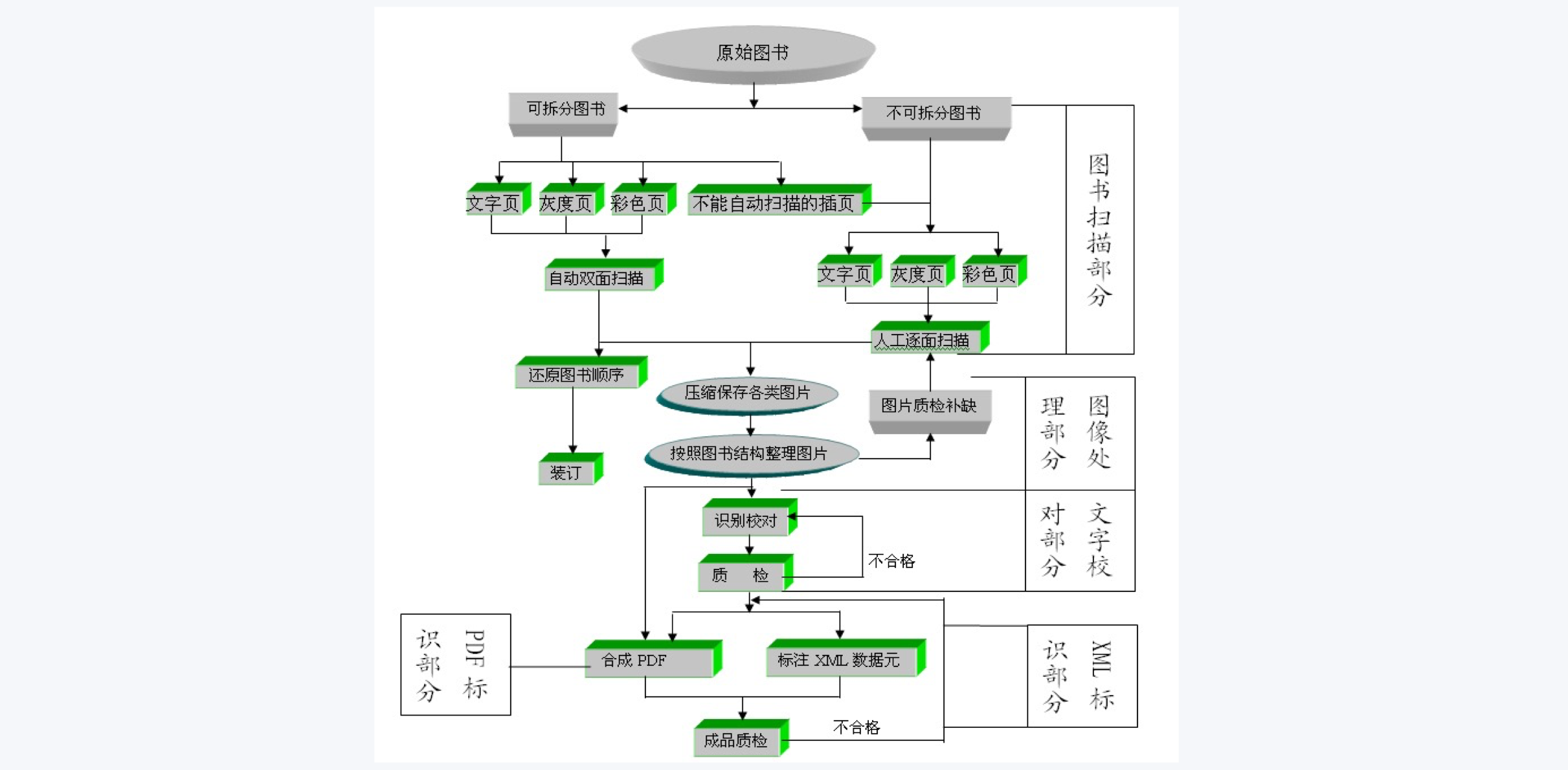
 扫描和修图
扫描和修图
按照日期、版面清点数量,确认其完整性、可识别性、可扫描性。选择纸质出版物中保存质量最佳的版本,以保证扫描质量的最优化。在核对过程中同时记录版面的残、缺、漏、损页,通过记入交接登记表单,详细记录出版物的缺损情况。并及时将版面的残、缺、漏、损等情况及时与出版单位汇报,以便进行资料补充。

 清点核对
清点核对
根据出版物不同版面大小,适配专业扫描设备进行扫描。对扫描的电子图像进行纠偏、去污、去黑边等处理。根据图像质量和资料质量,针对性地进行字迹锐化、去除图像杂点、去除图像局部脏点等处理工作。

 OCR文字识别和校对
OCR文字识别和校对
OCR识别技术是自动识别图片上汉字、数字、字母等信息的计算机应用技术。对于纸张完好,印刷精良的报刊,保证识别最佳效果;对于早期报纸,出于印刷技术和保存环境的原因,识别率降低,进行多次校对以保证数据最终输出质量。对于个别特殊文字,需要通过人工造字修字处理,确保文章的完整性。

 PDF还原、输出
PDF还原、输出
输出的PDF让其图像层和文字层的文字定位准确,保证反显区域与文字区域相差1/3字符以内。软件可以通过对字、行、块来调整。

 文章标引
文章标引
将完成识别校对的数字化文字内容按照不同字段进行标引(如标题、作者、时间、版名、版次等)。对图片、广告、插图时,单独制作成JPG图片,统一按照出版日期进行命名。

 NLP智能标引和XML输出
NLP智能标引和XML输出
通过智能著录标签技术,进一步提升数据品质,细化数据粒度。对于人工处理好的半成品数据,通过NLP智能标引技术,对每篇文章的文章摘要、报道对象、人物、来源、地点、体裁等著录项目进行自动提取标引。文章关联信息和文章客观信息著录项目(红色标签)与智能语义分析著录项目(蓝色标签),极大丰富了文章的新闻属性粒度,通过结构化提升了数据品质,为数据基础应用夯实了基础。
将报名—日期—版面—文章等信息进行关联,形成标签丰富、著录完整、结构合理、格式合规的XML数据文件,进行保存和备份,准备输出至数据库。
 自然语义数据智能著录技术
自然语义数据智能著录技术
将XML文件、PDF版面文件导入到数据库中,并且建立对应关联。数据库自动对入库数据文件质量实施自检,对信息缺失、重复信息等问题文件进行报警,不允许入库。
数据品质要求符合以下几项:
1.报纸扫描采用彩色格式、分辨率400–600 DPI,原始资料质量欠佳时,通过提高扫描分辨率保证图像清晰;
2.图像的偏斜角度小于5度;
3.版面和数字化内容关联准确率100 % ;
4.文字及符号错误率低于万分之一;